Зависимые и независимые случайные величины. Условные законы распределения и условные числовые характеристики
При изучении системы случайных величин зависимость меж-
ду составляющими X и Y может быть более или менее тесной.
Случайные величины X и Y называются независимыми, если
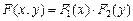 .
.
Для дискретных случайных величин X и Y это требование эквивалентно равенству
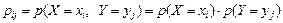 , (3.13)
, (3.13)
где 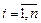 и
и 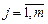 , а для непрерывных случайных величин условие непрерывности равно
, а для непрерывных случайных величин условие непрерывности равно
 . (3.14)
. (3.14)
Если случайные величины X и Y зависимы, то необходимо ввести понятие условного закона распределения и условной плотности распределения.
Распределение одной случайной величины, входящей в систему, найденное при условии, что другая случайная величина, входящая в систему, приняла определенное значение, называется условным законом распределения.
Для двумерной дискретной случайной величины (X,Y), принимающей значения ( 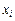 ,
, 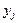 ) и с вероятностями
) и с вероятностями 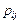 , можно определить условную вероятность
, можно определить условную вероятность 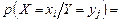
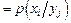 , пользуясь аксиомой умножения:
, пользуясь аксиомой умножения:
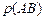 =
= 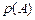 ×
× 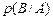
= 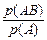 ,
,
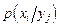 =
= 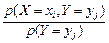 =
= 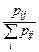 . (3.15)
. (3.15)
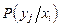 =
= 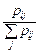 . (3.16)
. (3.16)
Для непрерывных случайных величин аналогичным образом определяется условная плотность распределения:
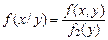 и
и 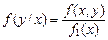 . (3.17)
. (3.17)
Условная плотность распределения обладает всеми свойствами безусловной плотности распределения.
В случае независимости случайных величин X и Y все условные плотности распределения совпадают с безусловными, т.е.
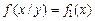 ;
; 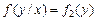 .
.
И наоборот, различие условных и безусловных плотностей распределения означает зависимость случайных величин.
Для зависимых случайных величин вводятся понятия условных числовых характеристик.
Условное математическое ожидание в дискретном случае:
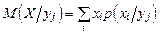 ;
; 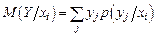 .
.
Условное математическое ожидание в непрерывном случае:
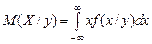 ;
; 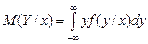 . (3.18)
. (3.18)
Условная дисперсия в дискретном и непрерывном случае имеет вид:
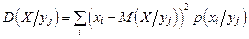 ;
;
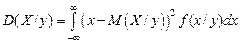 . (3.19)
. (3.19)
Из определения условных математических ожиданий следует, что  – это функция от y, а
– это функция от y, а 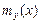 – функция от x. Причем, если система случайных величин
– функция от x. Причем, если система случайных величин 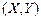 непрерывна, то функции
непрерывна, то функции 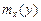 и будут также непрерывными. Уравнения
и будут также непрерывными. Уравнения 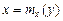 и
и 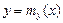 называются уравнениями регрессии X по Y
называются уравнениями регрессии X по Y
и Y по X соответственно, а графическое их изображение на плоскости  называется линиями регрессии.
называется линиями регрессии.
В качестве количественной характеристики степени зависимости случайных величин X и Y часто используют коэффициент корреляции  (см. формулу (3.12)), но он характеризует лишь степень линейной зависимости. Это следует из его свойств:
(см. формулу (3.12)), но он характеризует лишь степень линейной зависимости. Это следует из его свойств:
1) 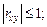
2) если 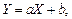 где a и b = const, то
где a и b = const, то 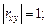
3) если Х и Y независимы, то 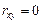 .
.
Пример 1.Плотность распределения системы случайных величин (X,Y) имеет вид:
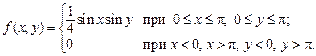
Определить, зависимы или независимы составляющие X и Y.
Р е ш е н и е. Вычислим плотности распределения составляющих, используя формулы (3.9) и (3.10) при 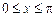 и
и 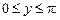
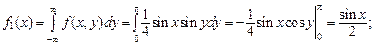
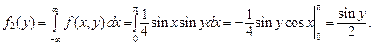
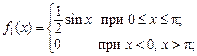
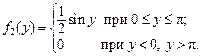
Случайные величины X и Y независимы, так как выполняется условие (3.14):
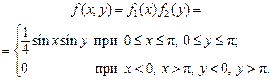
Пример 2.Плотность распределения двухмерной случайной величины имеет вид:

а) зависимы или независимы составляющие X и Y;
б) условные математические ожидания и условные дисперсии.
Р е ш е н и е. а) Плотность распределения составляющей X по формуле (3.9)
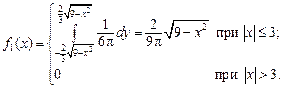
Аналогично для составляющей Y по формуле (3.10):
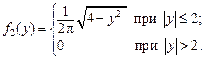
Очевидно, что условие (3.14) не выполняется. Таким образом, X и Y зависимы.
б) Найдем сначала условные плотности распределения 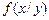 и
и  по формулам (3.17):
по формулам (3.17):
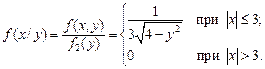
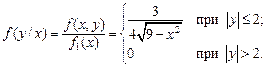
Найдем условные математические ожидания по формулам (3.18):
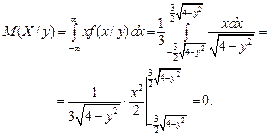
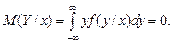
Найдем условную дисперсию по формуле (3.19):
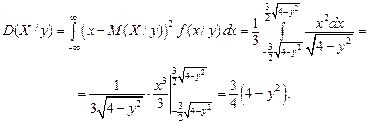
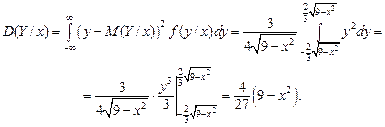
Пример 3.Закон распределения дискретной двумерной случайной величины задан табл. 3.3:
studopedia.info
5.5. Зависимые и независимые случайные величины.
При изучении систем случайных величин всегда следует обращать внимание на степень и характер их зависимости. Эта зависимость может быть более или менее тесной.
Понятие о независимых случайных величинах — одно из важных понятий теории вероятностей.
Определение 1. Случайная величина Y называется независимой от случайной величины X, если закон распределения величины Y не зависит от того, какое значение приняла величина X.
Для непрерывных случайных величин условие независимости Y от X может быть записано в виде:

Напротив, в случае, если Y зависит от X, то

Докажем, что зависимость или независимость случайных величин всегда взаимны: если величина Y не зависит от X, то и величина X не зависит от Y.
Действительно, пусть Y не зависит от X, тогда
Плотность совместного распределения согласно (5.4.5) и (5.4.6) можно записать


что и требовалось доказать.
Так как зависимость и независимость случайных величин всегда взаимны, можно дать новое определение независимых случайных величин.
Определение 2. Случайные величины X и Y называются независимыми, если закон распределения каждой из них не зависит от того, какое значение приняла другая. В противном случае величины X и Y называются зависимыми.
Для независимых непрерывных случайных величин теорема умножения законов распределения принимает вид:

Остановимся, несколько подробнее на важных понятиях о «зависимости» и «независимости» случайных величин.
Понятие «зависимости» случайных величин, которым мы пользуемся в теории вероятностей, несколько отличается от обычного понятия «зависимости» величин, которым мы оперируем в математике. Действительно, обычно под «зависимостью» величин подразумевают только один тип зависимости—полную, жесткую, так называемую функциональную зависимость. Две величины X и Y называются функционально зависимыми, если, зная значение одной из них, можно точно указать значение другой.
В теории вероятностей мы встречаемся с другим, более общим, типом зависимости — с вероятностной или «стохастической» зависимостью. Если величина Y связана с величиной X вероятностной зависимостью, то, зная значение X, нельзя указать точно значение Y, а можно указать только ее закон распределения, зависящий от того, какое значение приняла величина X.
Вероятностная зависимость между случайными величинами очень часто встречается на практике. Если случайные величины X и Y находятся в вероятностной зависимости, это не означает, что с изменением величины X величина Y изменяется вполне определенным образом; это лишь означает, что с изменением величины X величина Y имеет тенденцию также изменяться (например, возрастать или убывать при возрастании X).
Рассмотрим, например, две такие случайные величины: X — рост наугад взятого человека, Y — его вес. Очевидно, величины X и Y находятся в определенной вероятностной зависимости; она выражается в том, что в общем люди с большим ростом имеют больший вес.
scicenter.online
Нормальный закон распределения — введение

![]()
Приветствую дорогих читателей и подписчиков блога statanaliz.info. Продолжаем разговор о распределении данных. Как мы знаем, распределение может быть эмпирическим и теоретическим. Эмпирические данные всегда ограничены своей точностью и охватом возможных ситуаций. Поэтому для расчета интересующих вероятностей, пределов отклонений, размеров выборок и т.д. используют теоретические модели распределения случайной величины.
Самая известная статистическо-вероятностная модель – это закон нормального распределения. Нормальный закон, как и другие теоретические распределения, не является фиксированным уравнением зависимости одной переменной от другой. Фиксируется только характер этой зависимости. А вот конкретная форма распределения задается специальными параметрами в этом уравнении.
Например, всем понятно выражение типа у = аx + b – это уравнение прямой. Однако где конкретно она проходит и под каким наклоном, определяется параметрами а и b. Без заданных параметров невозможно четко представить эту линию. Также и с нормальным распределением. Ясно, что это функция, которая описывает тенденцию высокой концентрации значений около центра, но ее точная форма задается специальными параметрами, которые «подгоняют» модель под реальные данные.
Нормальный закон в теории статистики имеет фундаментальное значение. Он также лежит в основе ряда других распределений, поэтому ухватить самую суть желательно сразу. Вначале, возможно, будет слегка мутновато, но потом станет значительно легче, обещаю. Фактически после знакомства с нормальным распределением откроются новые горизонты использования статистических методов. Кстати, собственное логическое мышление под действием статистики также начинает деформироваться, в результате чего, общение с творческими личностями превращается в испытание. Ну да ладно.
Начнем с истории. Рассказываю, как сам слышал. Возможно, где-то перепутаю века, царей или континенты. В общем, я ни разу не историк.
Краткая история открытия нормального закона
История нормального закона насчитывает уже почти 300 лет. Говорят, первым причастным к открытию стал гражданин Абрахам де Муавр, который зафиксировал свои соображения по этому поводу в далеком 1733 году. Речь тогда шла о теоретическом приближении биномиального распределения при большом количестве наблюдений. Однако труды математика не были оценены по достоинству и Абрахама несправедливо забывают, когда речь идет об открытии нормального распределения. Широкое признание нормальный закон получил благодаря анализу выборочных данных.
Сейчас всем известно, что результаты выборочного исследования всегда ошибочны относительно истинного значения, которое исследователь и пытается оценить с помощью выборки. Если провести несколько измерений, то все они, скорее всего, будут отличаться друг от друга и, соответственно, от оцениваемого показателя по генеральной совокупности.
Статистика – наука исключительно практическая. Точность выводов здесь не пустой звук, а одна из насущных задач. В то же время вариация данных не способствует решению проблемы. Например, астрономы, проводя одни и те же наблюдения за небесными телами, все время получали различные результаты. Поначалу они считали, что всему виной их собственная небрежность и старались этот факт не сильно афишировать. Однако вопрос о постоянных отклонениях торчал занозой в ученом месте и не давал покоя пытливым умам тогдашних математиков. Как же быть с тем обстоятельством, что фактически нет возможности получить однозначный результат измерений? Что делать? Куда бежать? И какой из этого следует вывод? (последний вопрос от Ослика Иа).
И вот, эволюция мысли докатилась до того, что в светлую голову гражданина по имени Даниил Бернулли пришла замечательная мысль: разброс данных у самых различных явлений имеет что-то общее. Так, он сравнил разброс отклонений в астрономических наблюдениях с разбросом попаданий лучника в мишень и обнаружил, что и там и там максимальная концентрация результатов приходится на область относительно близкую к среднему значению, в то время как значительные отклонения происходят гораздо реже. Даниил подумал: а с чего бы это? И развивая успех, предложил соответствующий математический закон. Однако на этот раз ему не фартануло – закон оказался неверным. Кстати, этот Даниил был племянником другого Бернулли по имени Якоб. Того самого, который придумал закон больших чисел и процесс своего имени (когда в некотором эксперименте имеют место только два возможных исхода: благоприятный и неблагоприятный).
Тем не менее, идея об универсальном распределении ошибок измерений не осталась не замеченной, и немного позже другие ученые все-таки сформулировали правильный закон о случайных отклонениях. К открытию стали причастны Карл Фридрих Гаусс и Пьер-Симон Лаплас.
Гаусс вывел закон о распределении ошибок, чем и увековечил память о себе названием соответствующей функции (1809 г.). Чуть позже (в 1812 г.) П. Лаплас получил интеграл, который сегодня известен как функция нормального распределения.
Лаплас также обнаружил замечательную закономерность и сформулировал центральную предельную теорему (ЦПТ), согласно которой сумма большого количества малых и независимых величин имеет нормальное распределение. Центральная предельная теорема далее многократно уточнялась и видоизменялась, но суть ее осталась прежней. Таким образом, история открытия нормального закона насчитывает более 200 лет. Начиная от открытия Муавра, до окончательных формулировок ЦПТ в середине 20-го века. На сегодня мы имеем довольно развитый математический аппарат для анализа нормально распределенных данных.
На всякий случай еще раз отмечу, что приведенная выше история – это фривольный пересказ того, что я читал. Для серьезного изучения вопроса лучше обратиться к специализированной литературе.
Закон нормального распределения
Прежде чем погружаться в мир формул, крайне важно получить наглядное представление о предмете. Поэтому предлагаю начать с рисунка, с помощью которого далее будут изложены основные сведения о нормальном законе. Итак, функция плотности нормального распределения, она же функция Гаусса, имеет следующий вид.

Кривая Гаусса по форме несколько напоминает колокол, поэтому график нормального закона часто еще называют колоколообразной кривой. Если вдруг увидите термин «колоколообразная кривая», знайте, что речь идет о нормальном распределении.
Как видно, у графика имеется «горб» в середине и резкое снижение плотности по краям. В этом заключается суть нормального распределения. Другими словами, вероятность того, что случайная величина окажется около центра гораздо выше, чем то, что она сильно отклонится от середины. Смотрим на картинку.

На рисунке выше изображены два участка под кривой Гаусса: синий и зеленый. Основания, т.е. интервалы, у обоих участков равны. Но заметно отличаются высоты. Синий участок удален от центра, и имеет существенно меньшую высоту, чем зеленый, который находится в самом центре распределения. Следовательно, отличаются и площади, то бишь вероятности попадания в обозначенные интервалы.
Теперь посмотрим на формулу, по которой нарисована колоколообразная кривая, т.е. на функцию Гаусса.

Выглядит немного пугающе, но сейчас разберемся. В функции плотности нормального распределения присутствует: две математические константы
π – соотношение длины окружности и его диаметра, равно примерно 3,142;
е – основание натурального логарифма, равно примерно 2,718;
два параметра, которые задают форму конкретной кривой
m — математическое ожидание (в различных источниках могут использоваться другие обозначения, например, µ или a);
ну и сама переменная x, для которой высчитывается значение функции, т.е. плотность вероятности.
Константы, понятное дело, не меняются. Зато параметры — это то, что придает окончательный вид конкретному нормальному распределению. Отсюда и название: параметрическая функция или семейство параметрических функций. Напомню, есть и другие теоретические распределения, но мы сейчас говорим о нормальном.
Итак, конкретная форма нормального распределения зависит от 2-х параметров: математического ожидания (m) и дисперсии (σ 2 ). Кратко обозначается N(m, σ 2 ) или N(m, σ). Параметр m (матожидание) определяет центр распределения, которому соответствует максимальная высота графика. Дисперсия σ 2 характеризует размах вариации, то есть «размазанность» данных.
Параметр математического ожидания смещает центр распределения вправо или влево, не влияя на саму форму кривой плотности, что хорошо видно на самодвижущейся картинке.

А вот дисперсия определяет остроконечность кривой. Когда данные имеют малый разброс, то вся их масса сконцентрирована у центра. Если же у данных большой разброс, то они «размажутся» по широкому диапазону.

Плотность нормального распределения не имеет прямого практического применения (если не считать приближенных расчетов при использовании биномиального распределения). Вероятность того, что случайная величина окажется меньше некоторого значения x, определяется функцией нормального распределения:

Используя свойство непрерывного распределения, несложно рассчитать и любые другие вероятности, так как
statanaliz.info
Закон распределения это зависимость
Вероятностно-статистические методы воспроизводят как устойчивые, так и временные зависимости между экономическими явлениями и факторами. С помощью этих моделей можно обрабатывать данные статистического анализа, исследования закона распределения некоторой случайной величины, корреляционного (регрессионного) анализа получения количественной характеристики связей и зависимостей между различными технико-экономическими показателями. Кроме того, можно определять степень влияния каждого производственного фактора на изучаемый показатель или одновременно действующих факторов (для дисперсионного анализа) на технико-экономические показатели и выбирать из ряда факторов наиболее важные. [c.346]
Если между случайными величинами имеется автокорреляционная зависимость, то экстраполяционные значения случайной компоненты б f рассчитываются с помощью автокорреляционной функции [47]. [c.54]
Во-первых, вероятностный (стохастический) характер зависимости между многими экономическими показателями. Часто экономические явления отличаются особенностями случайного процесса. Например, уровень себестоимости добычи нефти и попутного газа оказывается под влиянием природных, производственных и организационных факторов. Однако в каждом отдельном случае влияние этих факторов неодинаково и результат их действия различный. Именно для таких случайных величин и процессов используются вероятностные методы исследования, одним из которых является корреляционный анализ. [c.59]
Корреляция — это статистическая зависимость между случайными величинами, не имеющими строго функционального характера, при которой изменение одной из них приводит к изменению математического ожидания другой. [c.112]
По виду зависимости между входными и выходными переменными модели, различают детерминированные и вероятностные модели. В детерминированных моделях выходные переменные однозначно определяются значениями входных переменных, при этом случайными, не предвиденными заранее воздействиями полностью пренебрегают. Для совокупности входных значений на выходе всегда получается единственно возможный результат. Вероятностные модели содержат случайные величины, благодаря которым для совокупности входных значений на выходе могут быть получены различные результаты. Вероятностные (или стохастические) модели учитывают фактор неопределенности информации, ее неточность или неполноту. Модели могут быть разделены на два класса по назначению [c.429]
Общим моментом для любой эконометрической модели является разбиение зависимой переменной на две части — объясненную и случайную. Сформулируем задачу моделирования самым общим, неформальным образом на основании экспериментальных данных определить объясненную часть и, рассматривая случайную составляющую как случайную величину, получить (возможно, после некоторых предположений) оценки параметров ее распределения. [c.10]
Пусть имеется р объясняющих переменных Х, . Хри зависимая переменная Y. Переменная Y является случайной величиной, имеющей при заданных значениях факторов некоторое распределение. Если случайная величина Y непрерывна, то можно считать, что ее распределение при каждом допустимом наборе значений факторов (х, х . хр) имеет условную плотность [c.11]
Объясняющие переменные Xj(j = . />) могут считаться как случайными, так и детерминированными, т. е. принимающими определенные значения. Проиллюстрируем этот тезис на уже рассмотренном примере продажи автомобилей. Мы можем заранее определить для себя параметры автомобиля и искать объявления о продаже автомобиля с такими параметрами. В этом случае неуправляемой, случайной величиной остается только зависимая переменная — цена. Но мы можем также случайным образом выбирать объявления о продаже, в этом случае параметры автомобиля — объясняющие переменные — также оказываются случайными величинами. [c.11]
Чтобы получить достаточно достоверные и информативные данные о распределении какой-либо случайной величины, необходимо иметь выборку ее наблюдений достаточно большого объема. Выборка наблюдений зависимой переменной 7 и объясняющих переменных Xj (j = 1. р) является отправной точкой любого эконометрического исследования. [c.13]
Под случайной величиной понимается переменная, которая в результате испытания в зависимости от случая принимает одно из возможного множества своих значений (какое именно — заранее не известно). [c.24]
Зависимость между двумя случайными величинами называется вероятностной (стохастической или статистической), если каждому значению одной из них соответствует определенное (условное) распределение другой. [c.38]
Ковариация двух случайных величин характеризует как степень зависимости случайных величин, так и их рассеяние вокруг точки (ах, ау). Ковариация — величина размерная, что затрудняет ее использование для оценки степени зависимости случайных величин. Этих недостатков лишен коэффициент корреляции. [c.39]
Из определения следует, что коэффициент корреляции — величина безразмерная — характеризует тесноту линейной зависимости между случайными величинами. [c.39]
При отсутствии линейной зависимости между зависимой и объясняющими(ей) переменными случайные величины SR — QR l(m 1) и s2=Qe/(n-m) имеют х2-распределение соответственно с т—1 и п—т степенями свободы, а их отношение — -распределение с теми же степенями свободы (см. 2.3). Поэтому уравнение регрессии значимо на уровне а, если фактически наблюдаемое значение статистики [c.72]
Детерминированные аналоги вероятностных ограничений на допустимые области варьирования технологических коэффициентов, количество ресурсов, пропускную способность технологических установок и выпуск конечных продуктов (см. (3.35) -(3.37) и (3.39)) в связи с тем, что случайные величины находятся только в правых частях неравенств, также имеют линейный вид и определяются в зависимости от задаваемых значений 7/ из следующих выражений [c.67]
Задаваемые построчные вероятности (уровни надежности) для каждого вида сырьевого ресурса и продукта определяются дифференциально, на основе экспертных оценок, или в зависимости от дисперсии рассматриваемых случайных величин. При этом в соответствии с [43] по тем продуктам, для которых невыполнение вероятностного ограничения вызывает большие потери или дополнительные расходы, уровень надежности задан большим. Как показали проведенные исследования, в соответствии с практическими требованиями оказывается целесообразным уровень надежности для случайных технологических коэффициентов выбирать в зависимости от дисперсии, а для случайных компонентов вектора ограничений — в ряде случаев на базе рекомендаций экспертов-технологов, работников планового отдела предприятия (так как ограничения на объемы переработки сырья, полу продуктов и вы пуск товарных продуктов определяются также вышестоящими органами и подвергаются неоднократным изменениям на этапе составления и реализации плана). При практических расчетах задаваемые вероятности изменяются от 0,75 до 0,96. [c.173]
На основе результатов предварительного анализа параметры модели, определяющие объемы перерабатываемых ресурсов, выпуск готовой продукции, производительности технологических установок и процессов, коэффициенты отбора нефтепродуктов, в зависимости от величины вариации принимаются детерминированными или случайными. Ограничения на математические ожидания невязок стохастических условий задачи выбираются в зависимости от вероятностных характеристик случайных величин с учетом рекомендаций экспертов-технологов и работников планового отдела предприятия. Аналогичным образом устанавливаются штрафы за коррекцию решения задачи. Для НПП топлив-но-масляного профиля задача календарного планирования включает порядка 1400 переменных, 940 уравнений, 300 верхних и 280 нижних граничных условий. Коэффициент заполненности матрицы условий задачи равен 0,21. [c.178]
Регрессионный анализ — один из наиболее разработанных методов математической статистики. Строго говоря, для реализации регрессионного анализа необходимо выполнение ряда специальных требований (в частности, х[,х2. хп у должны быть независимыми, нормально распределенными случайными величинами с постоянными дисперсиями). В реальной жизни строгое соответствие требованиям регрессионного и корреляционного анализа встречается очень редко, однако оба эти метода весьма распространены в экономических исследованиях. Зависимости в экономике могут быть не только прямыми, но и обратными и нелинейными. Регрессионная модель может быть построена при наличии любой зависимости, однако в многофакторном анализе используют только линейные модели вида [c.101]
Предполагается, что такие необходимые понятия теории вероятности, как случайная величина, вероятность, зависимые и независимые случайные величины, формула Байеса и функция распределения плотности вероятности, известны читателю. Необходимые сведения могут быть найдены в работе [c.253]
Для случайной величины с непрерывной и дифференцируемой функцией распределения вероятностей F(x) можно найти дифференциальный закон распределения вероятностей., выражаемый как производная F(x), то есть р(х) = dF(x)/dx. Эта зависимость называется плотностью распределения вероятностей. Плотность распределения р(х) обладает следующими свойствами [c.15]
Следовательно, коэффициент корреляции характеризует относительное отклонение математического ожидания произведения двух случайных величин от произведения математических ожиданий этих величин. Так как отклонение имеет место только для зависимых величин, то коэффициент корреляции характеризует степень этой зависимости. [c.95]
Коэффициент корреляции случайных величин X и 7 заключен в пределах между -1 и +1, достигая этих крайних значений только в случае линейной функциональной зависимости между X и 7 [c.95]
В качестве меры зависимости между случайными величинами используется коэффициент корреляции, определяемый по формуле [c.79]
В теории случайных процессов количественной мерой зависимости последовательности случайных величин является коэффициент автокорреляции [170]. Этот коэффициент принимает значения от 0 до 1. При значениях коэффициента автокорреляции, близких для соседних наблюдений к 0 (на практике меньших 0,2—0,3), считается, что процесс является белым шумом. Если же значения коэффициента автокорреляции близки к 1, то для данного процесса следует использовать различные системы регулирования с обратной связью. [c.347]
Выбор ставок для случайных сроков заимствования. Пусть зависимости оценок от сроков заимствования TI(TI) и Г2(т2) известны, ставки 7i (ri) и 72 (Г2) нужно выбрать по условию максимума средней прибыли с учетом балансовых условий (7.151), которые должны быть выполнены в среднем по TI и т2. Сами же сроки заимствования предполагаются случайными величинами с плотностями распределения Pi(n) и Р2(т2). [c.280]
Выведено уравнение, оптимизирующее количество интервалов группирования выборочных значений случайной величины в зависимости от объема выборки. Полученное уравнение оптимально не только при решении задач, связанных с определением вида закона распределения, но и при расчете с.к.о. с помощью эмпирической энтропии, при этом энтропийная оценка с.к.о. по точности не уступает интервальной оценке. [c.50]
Идея метода расчета допусков заключается в использовании функциональной зависимости между энтропией конкретного закона распределения непрерывной случайной величины и параметрами этого закона [c.88]
Временной (динамический) рад (time-series data). Временным (динамическим) рядом называется выборка наблюдений, в которой важны не только сами наблюдаемые значения случайных величин, но и порядок их следования друг за другом. Чаще всего упорядоченность обусловлена тем, что экспериментальные данные представляют собой серию наблюдений одной и той же случайной величины в последовательные моменты времени. В этом случае динамический ряд называется временным рядом. При этом предполагается, что тип распределения наблюдаемой случайной величины остается одним и тем же (например, нормальным), но параметры его меняются в зависимости от времени. [c.16]
Совокупную стоимостную оценку средств, участвующих в воспроизводственном процессе, обозначим А, собственный капитал, задействованный в денежном обороте предприятия, — PL Величины А и PI связаны друг с другом, однако эта зависимость не может быть функциональной. AvtPI представляют собой системы случайных величин (так как их изменения зависят от огромного числа внешних факторов, не всегда поддающихся учету) с частично выраженной вероятностной зависимостью. С изменением одной величины другая также должна изменяться и с наибольшей вероятностью связь между ними положительная, т.е. убывание или возрастание одной влечет такие же изменения другой. Так как эти величины постоянно изменяются во времени, их нужно рассматривать в динамике. [c.209]
При построении функций распределения реализации нефтепродуктов по областям Украинской ССР через распределительные базы учитывалось, что имеется существенная зависимость реализации нефтепродукта от дня недели. В качестве случайной величины использовалась qn = N jilMj, где fb — реализация распределительными базами /-и области в /-и день недели, М, —-месячная реализация по области, N—число рабочих дней в месяце. [c.258]
ВЕРОЯТНОСТНАЯ МОДЕЛЬ [sto hasti , probabilisti model] — 1. Модель, которая в отличие от детерминированной модели содержит случайные элементы (см. Случайная величина). Таким образом, при задании на входе модели некоторой совокупности значений, на ее выходе могут получаться различающиеся между собой результаты в зависимости от действия случайного фактора (см. также Неопределенность, Помехи). Другое название В.м. — стохастические модели. [c.45]
КОРРЕЛЯЦИЯ [ orrelation] — величина, характеризующая взаимную зависимость двух случайных величин, XnY, безразлично, определяется ли она некоторой причинной связью или просто случайным совпадением (ложной К.). Для того чтобы определить эту зависимость, рассмотрим новую случайную величину — произведение отклонения значений х от его среднего Мх и отклонения у от своего среднего My, Можно вычислить среднее значение новой случайной величины [c.155]
РАНГОВАЯ КОРРЕЛЯЦИЯ [rank orrelation] — мера зависимости между случайными величинами (наблюдаемыми признаками, переменными), когда эту зависимость невозможно определить количественно с помощью обычного коэффициента корреляции (см. Корреляция). Процедура установления Р.к. [c.299]
РЕГРЕССИЯ [regression] — зависимость среднего значения какой-либо случайной величины от некоторой другой величины или нескольких величин (в последнем случае — имеем множественную Р.). Следовательно, при регрессионной связи одному и тому же значению х величины X (в отличие от функциональной связи) могут соответствовать разные случайные значения величины У. Распределение этих значений называется условным распределением Y при данном X = х. [c.305]
СЛУЧАЙНЫЙ ПРОЦЕСС [random pro ess] (вероятностный, стохастический процесс) — случайная функция X t) от независимой переменной t (в экономике она чаще всего интерпретируется как время). Иначе говоря, это такой процесс, течение которого может быть различным в зависимости от случая, причем вероятность того или иного течения определена. Сп. можно рассматривать либо как множество реализаций функции X t), либо как последовательность случайных величин X t), заданных в различные моменты времени t.. Сп. дискретен или непрерывен в зависимости от того, дискретно или непрерывно множество его значений. Если дискретен аргумент t, то говорят о процессе с дискретным временем, или случайной последовательности. Если свойства процесса не зависят от начала отсчета времени, то такой [c.332]
СТОХАСТИЧЕСКАЯ ЗАВИСИМОСТЬ [sto hasti dependen e] — зависимость между случайными величинами, проявляющаяся в том, что изменение закона распределения одной из них происходит под влиянием изменения закона распределения другой. [c.347]
СТОХАСТИЧЕСКАЯ МОДЕЛЬ [sto hasti model] — такаяэкономико-математичес-кая модель, в которой параметры, условия функционирования и характеристики состояния моделируемого объекта представлены случайными величинами и связаны стохастическими (т.е. случайными, нерегулярными) зависимостями, [c.347]
КОРРЕЛЯЦИЯ (от лат. orrelatio — взаимосвязь) — зависимость между величинами, не имеющая строго функционального характера, при которой изменение одной из случайных величин приводит к изменению математического ожидания другой. Самая простая форма корреляции [c.295]
Определение вида закона распределения случайной величины по опытным данным занимает одно из центральных мест при обработке результатов экспериментов статистическими методами. Традиционный подход при решении задачи сводится к расчету параметров эмпирического распределения, принятию их в качестве оценок параметров генеральной совокупности с последующей проверкой сходимости эмпирического распределения с предполагаемым теоретическим по критериям х2 (Пирсона), А. (Колмогорова), со2. Такой подход имеет следующие недостатки зависимость методики обработки результатов эксперимента от предполагаемого теоретического распределения, большой объем вычислений, особенно при использовании критериев со2 и %2. Некоторые новые критерии [82] не имеют удовлетворительного теоретического обоснования, а в ряде случаев, как это показано в работе [82], не обладают достаточной мощностью. Б.Е. Янковский [133] предложил информационный способ определения закона распределения. Суть его в следующем. Если имеется выборка с распределением частос-тей Р, Р2> . Рп > то энтропия эмпирического распределения должна совпадать с энтропией предполагаемого теоретического распределения при верной нулевой гипотезе, т. е. должно выполняться равенство [c.27]
economy-ru.info